
مقدمه
آزمون تافل برای بسیاری از زبانآموزان، بهویژه در بخشهای رایتینگ و اسپیکینگ، تنها یک آزمون زبان نیست، بلکه معیاری تعیینکننده برای آینده تحصیلی و مهاجرتی آنهاست. با این حال، یکی از بزرگترین چالشهای داوطلبان تافل، نداشتن بازخورد دقیق، استاندارد و قابل اتکا بر روی پاسخهای نوشتاری و گفتاری است. تصحیحهای انسانی—حتی در بهترین حالت—معمولاً محدود، زمانبر و پرهزینهاند و در بسیاری از موارد به دلیل تفاوت سلیقهی مصححان، انسجام و شفافیت لازم را ندارند. از سوی دیگر، هزینهی ارزیابی حرفهای تنها یک پاسخ رایتینگ یااسپیکینگ میتواند به حدود 5۰۰هزار تومان برسد؛ رقمی که برای تمرین مستمر و بلندمدت، برای بسیاری از داوطلبان عملاً غیرقابل پرداخت است.
در چنین شرایطی، استفاده از فناوریهای نوین، بهویژه هوش مصنوعی مبتنی بر روبریکهای رسمی ETS، میتواند راهحلی مؤثر و در دسترس باشد. در تستهلپر، ما با بهرهگیری از مدلهای پیشرفتهی هوش مصنوعی، سیستمی طراحی کردهایم که پاسخهای رایتینگ واسپیکینگ را دقیقاً بر اساس معیارهای نمرهدهی تافل تحلیل و ارزیابی میکند. این سرویس، علاوه بر ارائهی بازخورد ساختارمند، شفاف و غیرسلیقهای، امکان تمرین گسترده و مقرونبهصرفه را برای داوطلبان فراهم میکند؛ بهگونهای که کاربران میتوانند با هزینهای بسیار کمتر از سرویسهای سنتی، بارها و بارها پاسخهای خود را بازبینی کرده و بهصورت هدفمند برای آزمون واقعی آماده شوند.

تصحیح انسانی در مقابل تصحیح هوش مصنوعی
در فرآیند آمادگی برای آزمون تافل، دریافت بازخورد دقیق بر روی پاسخهای رایتینگ و اسپیکینگ نقش حیاتی دارد. بهطور کلی، تصحیح انسانی—در صورت انجام توسط مصححان واقعاً متخصص و آشنا با روبریکهای رسمی ای تی اس—میتواند از نظر دقت تحلیلی در سطح بسیار بالایی قرار داشته باشد. با این حال، این روش در عمل با سه محدودیت جدی مواجه است. نخست آنکه تعداد افراد و مؤسسات واقعاً واجد صلاحیت برای تصحیح استاندارد تافل در ایران بسیار محدود است. دوم، هزینهی بالای این نوع ارزیابی است؛ بهطوری که تصحیح حرفهای هر پاسخ میتواند صدها هزار تومان هزینه داشته باشد. سوم، فرآیند تصحیح انسانی معمولاً زمانبر است و در بسیاری از موارد، داوطلبان باید ۲ تا ۳ روز برای دریافت بازخورد هر پاسخ منتظر بمانند؛ امری که تمرین منظم و پیوسته را دشوار میکند.
در مقابل، تصحیح مبتنی بر هوش مصنوعی رویکردی متفاوت اما بسیار کارآمد را ارائه میدهد. اگرچه ارزیابیهای هوش مصنوعی ماهیتی تخمینی دارند و نمرهی ارائهشده معمولاً در بازهای حدود ±0.5 نمره (بازه 1 تا 6) نسبت به نمرهی واقعی آزمون قرار میگیرد، اما مزایای عملی این روش قابل چشمپوشی نیست. سیستمهای مبتنی بر AI میتوانند بهصورت آنی، بدون خستگی یا خطای انسانی، و با ثبات کامل در نمرهدهی، پاسخها را دقیقاً بر اساس معیارهای ETS تحلیل کنند. علاوه بر این، امکان تصحیح همزمان چندین پاسخ، ارائهی بازخورد جزئی و ساختارمند، و هزینهی بسیار کمتر، هوش مصنوعی را به ابزاری ایدهآل برای تمرین گسترده و مستمر تبدیل کرده است.
در واقع، تصحیح انسانی و تصحیح هوش مصنوعی را نباید بهعنوان دو رویکرد رقیب مطلق در نظر گرفت، بلکه هر یک کارکرد خاص خود را دارند. تصحیح انسانی میتواند برای ارزیابیهای نهایی و محدود مفید باشد، در حالی که تصحیح مبتنی بر هوش مصنوعی بهترین گزینه برای تمرین روزانه، شناسایی الگوهای خطا، و بهبود تدریجی عملکرد داوطلبان تافل است—بهویژه زمانی که این سیستم بر اساس روبریکهای رسمی ETS طراحی شده باشد. جدول زیر مقایسهای از تصحیح انسانی و تصحیح مبتنی بر هوش مصنوعی ارائه میدهد.
جدول 1-مقایسهی تصحیح انسانی و تصحیح مبتنی بر هوش مصنوعی
| تصحیح انسانی | معیار مقایسه | |
تخمینی با اختلاف حدود ±0.5نمره (بازه 1 تا 6) |
| بسیار بالا (در صورت تخصص واقعی مصحح) | دقت تحلیلی |
کاملاً ثابت و یکنواخت |
| وابسته به سلیقه و خستگی مصحح | ثبات در نمرهدهی |
بسیار مقرونبهصرفه |
| بالا و غالباً غیرقابل تداوم | هزینه |
آنی |
| ۲ تا ۳ روز برای هر پاسخ | زمان دریافت بازخورد |
نامحدود |
| محدود | تعداد دفعات تمرین |
جزئی، ساختارمند و قابل تحلیل |
| گاه کلی و مبهم | شفافیت بازخورد |
دارد |
| ندارد | امکان تصحیح همزمان چند پاسخ |
طراحیشده بر اساس روبریک رسمی |
| وابسته به دانش مصحح | تطابق با روبریک ETS |

تصحیح هوش مصنوعی در مهارت رایتینگ
در مهارت رایتینگ آزمون تافل، صرفاً نوشتن بدون خطای گرامری کافی نیست؛ داوطلب باید بتواند پاسخ خود را بهصورت هدفمند، منسجم و متناسب با نوع تسک ارائه دهد. سیستم تصحیح هوش مصنوعی تستهلپر بهگونهای طراحی شده است که پاسخهای نوشتاری را دقیقاً بر اساس معیارهای ارزیابی تافل تحلیل کند. این سیستم علاوه بر ارائهی نمره، بازخوردی جزئی و ساختارمند در حوزههای مختلف نوشتار ارائه میدهد و در نهایت، نسخهای بهبودیافته از پاسخ داوطلب را پیشنهاد میکند تا مسیر پیشرفت کاملاً شفاف باشد.
تصحیح هوش مصنوعی در تسک Write an Email
در تسک Write an Email، داوطلب باید توانایی خود را در برقراری ارتباط نوشتاری مؤثر، با لحن و ساختار مناسب، نشان دهد. سیستم هوش مصنوعی تستهلپر در این بخش، پاسخ داوطلب را در چهار مؤلفهی اصلی ارزیابی میکند:بسط و توسعه محتوا (Elaboration)، سازماندهی متن (Organization)، رعایت قراردادهای اجتماعی و لحن مناسب (Social Conventions) و دقت زبانی شامل گرامر و واژگان (Grammar & Vocabulary). هر یک از این مؤلفهها بهصورت جداگانه در بازهی نمرهای ۰ تا ۷.۵ ارزیابی میشوند و در نهایت، مجموع آنها به مقیاس 1 تا 6 آورده میشود.
علاوه بر نمرهدهی، سیستم بازخوردی دقیق ارائه میدهد که نشان میدهد کدام بخشهای ایمیل نیاز به بهبود دارند؛ از شفافیت پیام و تناسب لحن گرفته تا انسجام پاراگرافها و انتخاب واژگان. در پایان نیز یک نسخهی اصلاحشده و پیشنهادی از ایمیل ارائه میشود تا داوطلب بتواند تفاوت میان پاسخ خود و یک پاسخ قویتر را بهصورت عملی مشاهده کند.جدول زیر معیارهای نمرهدهی ای تی اس برای این تسک را ارائه کرده است.
جدول 2- معیار نمرهدهی تسک Write an Email رایتینگ
نمره | توصیف سطح | معیارهای دقیق | |
5
|
کاملاً موفق |
| |
4 |
موفق | - بسط کافی برای هدف ایمیل - واژگان و ساختار مناسب - عمدتاً رسمی و مناسب - تعداد اندک خطا | |
3 |
نیمهموفق | - بسط ناقص اما قابل فهم - دایره لغات و ساختار متوسط - برخی خطاهای قابل توجه در گرامر و کاربردها
| |
2
|
بیشتر ناموفق | - بسط کم، گاهی نامرتبط - ساختار محدود و واژگان کمدامنه - خطاهای متعدد که پیام را مبهم میسازد | |
1 |
ناموفق | - تقریباً بدون بسط - زبان تلگرافی یا کلمات جدا - خطاهای شدید و مکرر - بخش عمده متن از prompt کپی شده | |
0 | بدون پاسخ یا نامربوط | -بدون پاسخ، کاملاً نامفهوم، یا غیر انگلیسی |
راهنمایی تصحیح پاسخ خود در این تسک با هوش مصنوعی تست هلپر
برای تصحیح پاسخ خود توسط هوش مصنوعی تست هلپر، مطابق مراحل زیر پیش بروید:
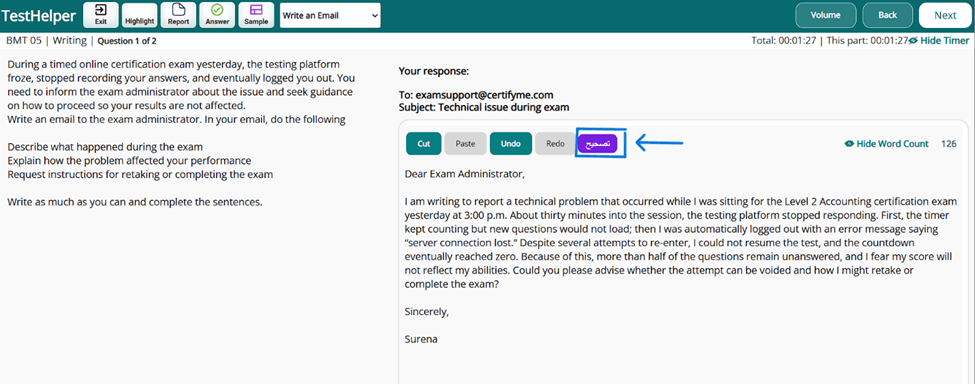
1- پس از نوشتن پاسخ خود در حالت practice یا test به صفحه پاسخ خود رجوع کرده و مطابق شکل پایین روی دکمه "تصحیح" کلیک کنید.
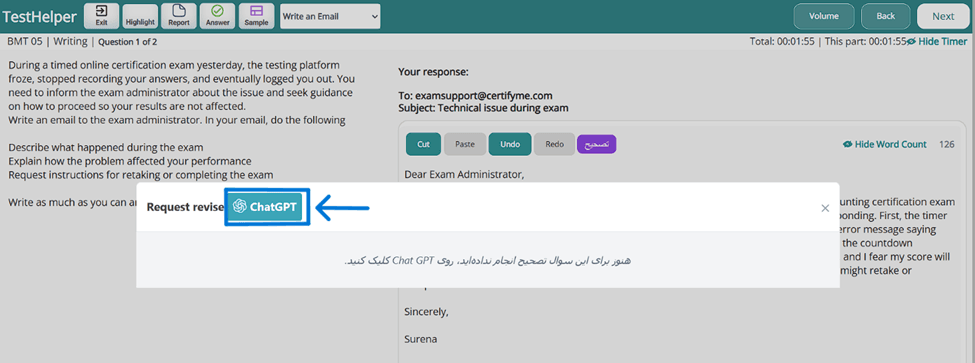
2- پس از کلیک، صفحهای مطابق شکل زیر نمایش داده میشود که تصحیحهای پیشین شما روی این پاسخ خاص نیز در صورت وجود به نمایش در میآیند. برای ادامه تصحیح، مطابق شکل زیر روی آیکن ChatGPT کلیک کنید و تایید کنید.
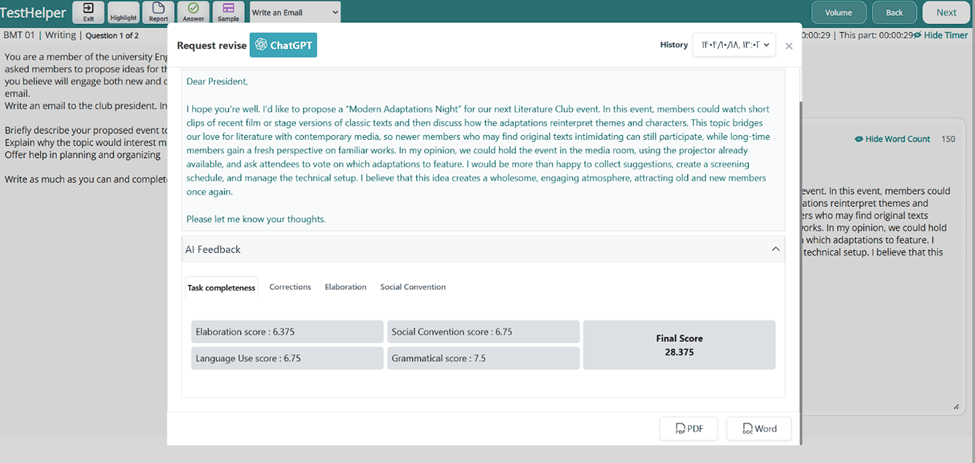
3- پس از اینکه پاسخ توسط هوش مصنوعی بررسی شد، مطابق شکل زیر، صفحهای از فیدبک و تحلیل هوش مصنوعی تست هلپر از پاسخ شما ارائه میشود. برای این تسک، هوش مصنوعی متن شما را به صورت جداگانه با 4 معیار Elaboration، Social Conventions، Grammar و Language Use میسنجد و در هر حوزه به متن شما از 0 تا 7.5 نمرهای میدهد. جمع این 4 نمره به مقیاس 1 تا 6 آورده میشود. توجه داشته باشید که بخش Elaboration پاسخ شما را از نظر میزان تکمیلبودن و پوشش خواستههای صورت سوال، بخش Social Conventions پاسخ شما را از نظر ساختار ایمیل اصولی و لحن ایمیل با توجه به سناریو، بخشGrammar پاسخ شما را از نظر صحت گرامری و نگارشی، و بخش Language Use متن شما را از نظر کاربرد صحیح واژگان با نگارش صحیح و در جای درست و به صورت رسمی بررسی میکند.
تصحیح هوش مصنوعی در تسک Write for an Academic Discussion
در تسک Write for an Academic Discussion، تمرکز اصلی بر توانایی داوطلب در مشارکت مؤثر در یک بحث آکادمیک است. در این بخش، سیستم هوش مصنوعی تستهلپر پاسخ داوطلب را با در نظر گرفتن محتوای کلی بحث و پاسخهای سایر شرکتکنندگان تحلیل میکند. یکی از نکات کلیدی برای کسب نمرهی بالا در این تسک، ارائهی دیدگاهی مستقل و غیرتکراری است؛ بهطوری که پاسخ داوطلب نباید همپوشانی قابلتوجهی با نظرات دو دانشجوی دیگر داشته باشد.
سیستم تصحیح در این تسک بر سه معیار اصلی تمرکز دارد: میزان تحقق هدف تسک و مشارکت مؤثر در بحث (Task Fulfillment / Contribution)، سازماندهی و انسجام پاسخ (Organization) و دقت زبانی شامل گرامر و واژگان (Grammar & Vocabulary).پس از ارزیابی، علاوه بر ارائهی نمره، بازخوردی تحلیلی در مورد کیفیت استدلال، وضوح بیان و انسجام پاسخ ارائه میشود. در نهایت، یک پاسخ بهبودیافتهی پیشنهادی در اختیار داوطلب قرار میگیرد تا مسیر رسیدن به پاسخهای سطح بالا بهصورت ملموس مشخص شود. جدول زیر معیارهای نمرهدهی ای تی اس برای این تسک را ارائه کرده است.
جدول 3- معیار نمرهدهی تسک Academic Discussion رایتینگ
نمره | توصیف سطح | معیارهای دقیق |
5
|
کاملاً موفق | - استدلال کاملاً بسطیافته، مرتبط و با مثال/توضیح - ساختارهای متنوع و واژههای دقیق - تقریباً بدون خطا |
4 |
موفق | - توضیح و مثال کافی، مرتبط و قابل فهم - واژگان مناسب با ساختارهای مختلف - خطاهای اندک |
3 |
نیمهموفق | - بخشی از توضیحات ناقص یا نامرتبط - تنوع محدود در ساختارها/واژگان - خطاهای قابل توجه اما قابل فهم |
2
|
بیشتر ناموفق | - ایدهها کمارتباط یا ناقص - دامنه واژگان و ساختار بسیار محدود - خطاهای متعدد گرامری/ساختاری |
1 |
ناموفق | - ایدههای بسیار کم، نامنسجم - دامنه لغات و ساختار بسیار ضعیف - خطاهای شدید |
0 | بدون پاسخ یا نامربوط | -بدون پاسخ، کاملاً نامفهوم، یا غیر انگلیسی |
راهنمایی تصحیح پاسخ خود در این تسک با هوش مصنوعی تست هلپر
برای تصحیح پاسخ خود توسط هوش مصنوعی تست هلپر، مطابق مراحل زیر پیش بروید:
1- پس از نوشتن پاسخ خود در حالت practice یا test به صفحه پاسخ خود رجوع کرده و روی دکمه "تصحیح" کلیک کنید.
2- پس از کلیک، صفحهای مطابق شکل زیر نمایش داده میشود که تصحیحهای پیشین شما روی این پاسخ خاص نیز در صورت وجود به نمایش در میآیند. برای ادامه تصحیح، مطابق شکل زیر روی آیکن ChatGPT کلیک کنید و تایید کنید.
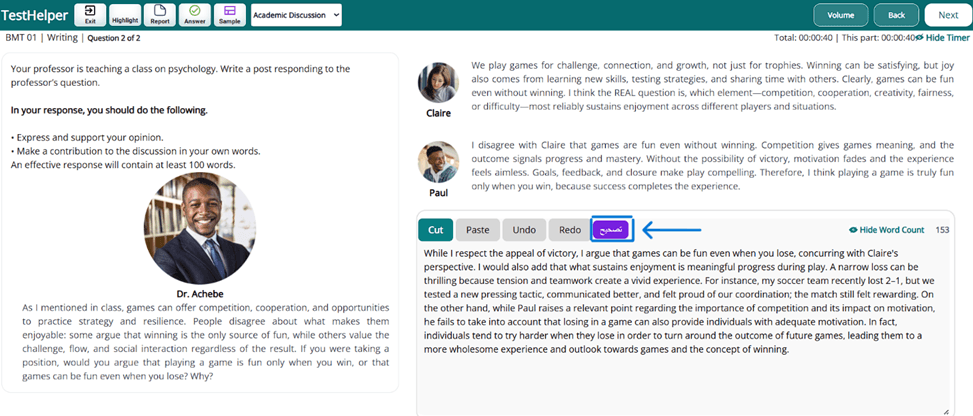
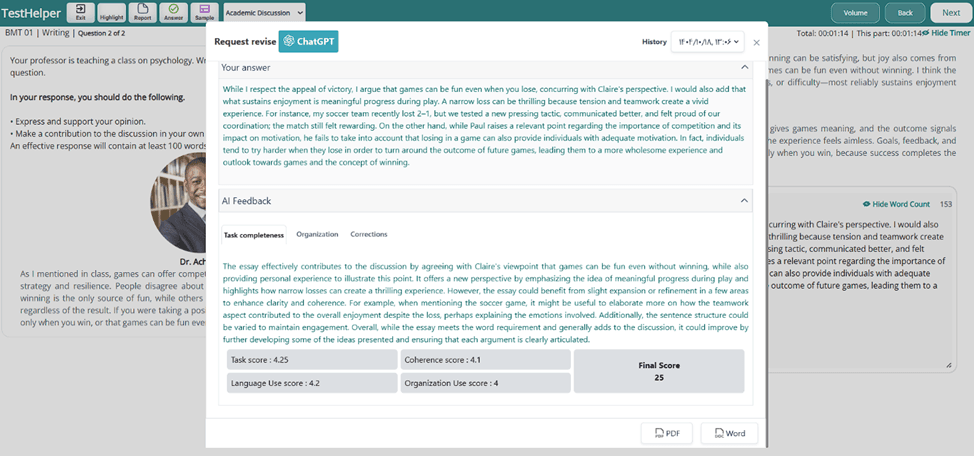
3- پس از اینکه پاسخ توسط هوش مصنوعی بررسی شد، مطابق شکل زیر، صفحهای از فیدبک و تحلیل هوش مصنوعی تست هلپر از پاسخ شما ارائه میشود. برای این تسک، هوش مصنوعی متن شما را به صورت جداگانه با 4 معیار Task، Coherence & Organization، Grammar و Language Use میسنجد و در هر حوزه به متن شما از 0 تا 5 نمرهای میدهد. جمع این 4 نمره به مقیاس 1 تا 6 آورده میشود. توجه داشته باشید که بخش Task پاسخ شما را از نظر میزان تکمیلبودن و پوشش خواستههای صورت سوال، بخشCoherence & Organization پاسخ شما را از نظر ساختار اصولی پاسخ رسمی با توجه به سناریو، بخش Grammar پاسخ شما را از نظر صحت گرامری و نگارشی، و بخش Language Use متن شما را از نظر کاربرد صحیح واژگان با نگارش صحیح و در جای درست و به صورت رسمی بررسی میکند. همچنین در بخش corrections متن تصحیحشده و دارای فیدبک شما نیز به شما تحویل میشود.
تصحیح هوش مصنوعی در مهارت اسپیکینگ
در مهارت اسپیکینگ آزمون تافل، ارزیابی صرفاً به روان صحبت کردن محدود نمیشود، بلکه دقت تلفظ، انسجام پاسخ، تکمیل صحیح تسک و مدیریت زمان نیز نقش تعیینکنندهای دارند. سیستم تصحیح هوش مصنوعی تستهلپر با بهرهگیری از یک پرامپت جامع و چندلایه طراحی شده است که هر پاسخ گفتاری را به اجزای مختلف تقسیم کرده و هر بخش را بهصورت مستقل ارزیابی میکند. این سیستم برای هر تسک، نمرهای از 1 تا 6 ارائه میدهد و همزمان بازخورد تحلیلی و آموزشی در اختیار داوطلب قرار میدهد.
فرآیند ارزیابی بهصورت مرحلهای انجام میشود؛ به این معنا که معیارهایی مانند دقت تلفظ، محتوا، ساختار پاسخ و دقت زبانی ابتدا در قالب زیرپرامپتهای مجزا بررسی میشوند و سپس نتایج آنها در یک پرامپت نهایی تجمیع میشود تا نمرهی کلی و بازخورد نهایی تولید شود. این ساختار چندبخشی باعث میشود ارزیابی نهایی منسجم، شفاف و همراستا با روبریکهای رسمی ETS باشد.

تصحیح هوش مصنوعی در تسک Listen and Repeat
در تسک Listen and Repeat، هدف اصلی سنجش توانایی داوطلب در درک دقیق گفتار و بازتولید آن با تلفظ صحیح، لحن مناسب و حداقل خطای معنایی است. در سیستم تستهلپر، پاسخ صوتی داوطلب ابتدا با استفاده از مدل Whisper به متن تبدیل میشود. این مدل برای هر واژه یک ضریب اطمینان تلفظ در بازهی ۰تا ۱ اختصاص میدهد؛ بهطوری که عدد ۱ نشاندهندهی تلفظ کاملاً صحیح است.
بر اساس این دادهها و در کنار معیارهای تعیینشده در روبریکهای ای تی اس—از جمله دقت، کامل بودن پاسخ، لحن و میزان تطابق با جملهی اصلی—هر یک از هفت جملهی این تسک بهصورت جداگانه ارزیابی میشود. در نهایت، عملکرد داوطلب در تکرار تمامی جملات با یکدیگر تجمیع شده و نمرهی کلی این تسک محاسبه میشود. در این ارزیابی، لهجه (accent) بهخودیخود معیار منفی محسوب نمیشود و تنها تلفظهایی که باعث اختلال در درک یا دقت واژهها شوند، در نمرهدهی تأثیر خواهند داشت. جدول زیر معیارهای نمرهدهی ای تی اس برای این تسک را ارائه کرده است.
جدول 4- معیار نمرهدهی تسک Listen and Repeat اسپیکینگ
نمره | توصیف سطح | معیارهای دقیق |
5
|
تکرار کاملاً دقیق | - جمله بهطور کامل و دقیق تکرار میشود - کاملاً قابل فهم و بدون تغییر در معنا |
4 |
تکرار تقریباً دقیق با تغییرات جزئی | - تغییرات کوچک در کلمات عملکردی یا نشانههای دستوری، بدون ایجاد تغییر جدی در معنا - ممکن است یک کلمه حذف یا با کلمهای مرتبط جایگزین شود - تلفظ کمی مبهم در یک یا دو کلمه مجاز است |
3 |
تکرار نسبتاً کامل ولی با اشتباهات معنایی | - اکثر کلمات و ایدههای اصلی وجود دارند - چند کلمه عملکردی/محتوایی حذف یا تغییر یافتهاند - جمله کامل است ولی گاهی فهم معنا دشوار میشود |
2
|
تکرار ناقص و نادقیق | - بخش زیادی از جمله حذف شده است - جمله ناقص و بدون استقلال معنایی - تلفظ و پیوستگی بسیار ضعیف |
1 |
تلاش حداقلی | - تنها چند کلمه تکرار شده و بیشتر جمله از بین رفته است - تقریباً نامفهوم |
0 | بدون پاسخ یا نامربوط | -بدون پاسخ، کاملاً نامفهوم، یا غیر انگلیسی |
تصحیح هوش مصنوعی در تسک Take an Interview
در تسک Take an Interview، داوطلب باید به سؤالات مطرحشده پاسخهایی مرتبط، منسجم و از نظر زبانی دقیق ارائه دهد. سیستم تصحیح هوش مصنوعی تستهلپر در این بخش، پاسخ گفتاری را هم از نظر محتوا و هم از نظر ساختار بررسی میکند. معیارهایی مانند تحقق هدف تسک (Task Fulfillment)، سازماندهی پاسخ، روانی گفتار، دقت گرامری و واژگانی و انسجام کلی بهصورت همزمان در ارزیابی لحاظ میشوند و نمره نهایی به مقیاس 1 تا 6 آورده میشود.
علاوه بر این، مدیریت زمان پاسخ نیز بخشی از فرآیند ارزیابی است و میزان تناسب طول پاسخ با محدودیت زمانی تعیینشده در تسک بررسی میشود. بازخورد ارائهشده در این بخش بهصورت متنی و تحلیلی است و همراه با نمایش متنی پاسخ داوطلب ارائه میشود؛ بهگونهای که کیفیت تلفظ واژگان با طیفی رنگی از قرمز (ضعیف) تا سبز (بسیار مطلوب) مشخص میشود. این نمایش بصری به داوطلب کمک میکند تا بهصورت دقیق ببیند کدام بخشهای پاسخ نیاز به بهبود دارند. جدول زیر معیارهای نمرهدهی ای تی اس برای این تسک را ارائه کرده است.
جدول 5- معیار نمرهدهی تسک Take an Interview اسپیکینگ
نمره | توصیف سطح | معیارهای دقیق | |
5
|
پاسخ کاملاً موفق | - پاسخ کامل، مرتبط و خوب بسطیافته - سرعت گفتار طبیعی با مکثهای مناسب - تلفظ کاملاً قابل فهم، استفاده درست از ریتم و لحن - گرامر و لغات دقیق و متنوع | |
4 |
پاسخ موفق |
| |
3 |
پاسخ متوسط/نسبی |
| |
2
|
پاسخ ناموفق | - ارتباط کمی با پرسش دارد و بسط ندارد - معنا غالباً نامشخص است - دامنه لغات و گرامر بسیار محدود | |
1 |
بسیار ناموفق | - ارتباط تنها در حد چند کلمه - تقریباً نامفهوم - شامل کلمات منفصل | |
0 | بدون پاسخ یا نامربوط | -بدون پاسخ، کاملاً نامفهوم، یا غیر انگلیسی |
تصحیح تستهلپر چه مزیتی نسبت به تصحیح خود فرد با اکانت پریمیوم هوش مصنوعی دارد؟
امروزه بسیاری از داوطلبان تافل به استفاده از هوش مصنوعی برای بازبینی پاسخهای رایتینگ و اسپیکینگ علاقهمند شدهاند و این موضوع کاملاً قابل درک است. با این حال، تفاوت اساسی میان استفادهی عمومی از یک مدل هوش مصنوعی و بهرهگیری از یک سیستم تصحیح تخصصی و آزمونمحور در همین نقطه شکل میگیرد. در تستهلپر، هوش مصنوعی نه بهصورت عمومی، بلکه در قالب یک ساختار ارزیابی دقیق و از پیش طراحیشده به کار گرفته میشود.
سیستم تصحیح تستهلپر بر پایهی پرامپتهای جامع و چندصفحهای طراحی شده است که هر یک بهصورت مستقل بر جنبهای مشخص از پاسخ تمرکز دارند؛ از دقت زبانی و انسجام گرفته تا تحقق هدف تسک و همراستایی با روبریکهای رسمی ای تی اس. این زیرپرامپتها طی زمان توسط متخصصان تافل تستهلپر—که خود سابقهی کسب نمرات کامل در بخشهای رایتینگ و اسپیکینگ آزمون واقعی را دارند—توسعه داده شده و بهطور منظم مورد بازبینی و بهبود قرار میگیرند. در نتیجه، ارزیابی نهایی حاصل تجمیع چند تحلیل تخصصی است، نه یک پاسخ کلی و عمومی.
علاوه بر این، برای افزایش دقت نمرهدهی، یک بانک دادهی سطحبندیشده از پاسخها با نمرات مختلف (در هر دو مهارترایتینگ و اسپیکینگ)در اختیار سیستم قرار داده شده است. این دادهها به هوش مصنوعی کمک میکند تا درک دقیقتری از این داشته باشد که یک پاسخ در هر سطح مهارتی، به چه نمرهای نزدیک است. چنین ساختاری باعث میشود نمرهدهی از ثبات بالاتری برخوردار باشد و اختلافهای غیرمنطقی در ارزیابی کاهش یابد—موضوعی که در استفادهی شخصی و بدون چارچوب از هوش مصنوعی معمولاً قابل تضمین نیست.
جدول 6-مقایسهی استفادهی شخصی از هوش مصنوعی پریمیوم و سیستم تصحیح تستهلپر
اکانت پریمیوم هوش مصنوعی (استفاده شخصی) | معیار مقایسه | |
اختصاصی، چندلایه و آزمونمحور | عمومی و وابسته به کاربر | نوع پرامپت |
طراحی و کنترلشده توسط متخصصین تست هلپر | وابسته به کیفیت پرامپت کاربر | همراستایی با روبریک ای تی اس |
بالا و یکنواخت | متغیر | ثبات نمرهدهی |
نرمالسازی بر اساس پاسخهای کاربران | قابل تغییر و ناپایدار | ساختار نمرهدهی |
دارد | ندارد | بانک دادهی سطحبندیشده |
مقرون به صرفه | بسیار بالا | هزینه |
دارد (دیکشنری، فلش کارد و ...) | ندارد | دسترسی به امکانات اشتراک مکمل |
دارد | ندارد | تصحیح رایگان روزانه |
نمرات هوش مصنوعی تستهلپر چقدر به نمرات کاربران در آزمون واقعی نزدیک است؟
یکی از پرسشهای طبیعی داوطلبان تافل هنگام استفاده از سیستمهای مبتنی بر هوش مصنوعی، میزان نزدیکی نمرات ارائهشده به نمرهی واقعی آزمون است. در تستهلپر، هدف از نمرهدهی هوش مصنوعی، ارائهی یک «پیشبینی قطعی» نیست، بلکه کالیبرهکردن سطح داوطلب و فراهمکردن مبنایی قابل اتکا برای سنجش میزان آمادگی اوست. به همین دلیل، نمرات ارائهشده همواره در کنار بازخورد تحلیلی و آموزشی معنا پیدا میکنند.
بر اساس تجربهی صدها داوطلب تافل که پیش از شرکت در آزمون واقعی از سیستم تصحیح تستهلپر استفاده کردهاند و پس از آزمون، نمرات خود را گزارش دادهاند، در اغلب موارد نمرات هوش مصنوعی تستهلپر با نمرهی واقعی آزمون در بازهای حدود ±0.5نمره (بازه 1 تا 6) همخوانی داشته است. بسیاری از کاربران اعلام کردهاند که نمرهی واقعی آنها یا بسیار نزدیک به نمرات تمرینی بوده، یا نهایتاً یک تا دو نمره بالاتر یا پایینتر از آن قرار گرفته است. این همخوانی نشان میدهد که سیستم میتواند تصویری واقعبینانه از سطح عملکرد داوطلب ارائه دهد.
البته باید توجه داشت که میزان دقت در مهارتهای مختلف یکسان نیست. در بخش رایتینگ، به دلیل ماهیت نوشتاری پاسخها و حذف عوامل اجرایی مانند استرس لحظهای یا محدودیت شدید زمانی، معمولاً همبستگی نمرات هوش مصنوعی با نمرهی واقعی بالاتر است. در مقابل، در بخش اسپیکینگ عواملی مانند شرایط ضبط صدا، فشار زمانی (برای مثال ۱۰ ثانیه برای تکرار هر جمله در تسک اول و ۴۵ ثانیه بدون زمان آمادهسازی در تسک دوم)، و استرس آزمون میتوانند باعث نوسان بیشتری در نمرهی واقعی شوند. با این حال، حتی در اسپیکینگ نیز بازهی نمرهای ارائهشده توسط سیستم تستهلپر برای اغلب داوطلبان قابل اتکا بوده است.
نکتهی مهم این است که ثبات نمره در تمرینها اهمیت بیشتری از یک نمرهی منفرد دارد. اگر داوطلبی در تمرینهای متعدد، بهطور پایدار در یک بازهی مشخص (مثلاً 4 تا 4.5) قرار بگیرد، احتمال زیادی وجود دارد که نمرهی واقعی او نیز در همان محدوده یا بسیار نزدیک به آن باشد. از این منظر، سیستم تصحیح هوش مصنوعی تستهلپر ابزاری مؤثر برای پایش روند پیشرفت و تشخیص آمادگی واقعی برای آزمون محسوب میشود.
در نهایت، تأکید بر این نکته ضروری است که تصحیح هوش مصنوعی در تستهلپر نقش مکمل دارد: ابزاری قدرتمند برای تمرین مستمر، دریافت بازخورد دقیق و تنظیم سطح عملکرد. در حالی که ارزیابیهای انسانی تخصصی همچنان دقیقترین مرجع برای قضاوت نهایی محسوب میشوند، استفادهی هوشمندانه از سیستم AI میتواند داوطلبان را با آمادگی بسیار بالاتری به آزمون واقعی برساند.
جمعبندی نهایی
در مسیر آمادگی برای آزمون تافل، بهویژه در مهارتهای رایتینگ و اسپیکینگ، دسترسی به بازخورد دقیق، استاندارد و مقرونبهصرفه یکی از مهمترین چالشهای داوطلبان است. تصحیح انسانی، در صورت انجام توسط متخصصان واقعی تافل، میتواند بسیار دقیق باشد، اما محدودیتهایی مانند هزینهی بالا، دسترسی محدود و زمانبر بودن، استفادهی مستمر از آن را برای بسیاری از داوطلبان دشوار میکند. در مقابل، سیستم تصحیح هوش مصنوعی تستهلپر با تکیه بر روبریکهای رسمی ETS، پرامپتهای چندلایهی تخصصی و بانک دادهی سطحبندیشده، امکان دریافت بازخورد ساختارمند، سریع و پایدار را برای تمرین مداوم فراهم کرده است.
تجربهی صدها داوطلب نشان میدهد که نمرات ارائهشده توسط هوش مصنوعی تستهلپر در اغلب موارد با نمرات آزمون واقعی اختلاف کمی دارند و میتوانند تصویر واقعبینانهای از سطح آمادگی داوطلب ارائه دهند. با ترکیب این سیستم تصحیح با آزمونهای شبیهسازیشده، ابزارهای آموزشی و بستههای مقرونبهصرفهی تستهلپر، داوطلبان میتوانند بهصورت هدفمند، پیوسته و با آگاهی دقیق از نقاط قوت و ضعف خود، برای آزمون تافل آماده شوند. در این چارچوب، هوش مصنوعی نه جایگزین قضاوت انسانی، بلکه مکملی قدرتمند برای تمرین مؤثر و افزایش آمادگی واقعی است.